
TEAM
1 x Design Manager
2 x Applied Scientist
Development Team
MY ROLE
Research Strategy
UX Research
AI-Evaluation
Data Analysis
DURATION
3 weeks
THE PROBLEM
The knowledge gap
Zalando's AI Assistant—a conversational tool that helps customers discover fashion through natural language had launched to early users and was preparing to scale to new markets.
But we had a critical problem: Nobody had a systematic view of how customers were actually using it. What were they asking for? Where was the assistant failing them? Were we even measuring success correctly? Without answers, we were making product decisions based on assumptions, not evidence.
IMPACT
The research directly shaped the product roadmap and improved assistant performance in the first month of launch.
14% High value actions HVAs
increase in the first month of launch
3 key insights
driving next product iterations
1 scalable
human-in-the-loop framework for continuous improvement
UNDERSTANDING THE SPACE
Aligning on what we didn't know
I started by mapping questions and assumptions across Design, Engineering, and Applied Science.
This revealed a shared gap: The team was building a scalable platform, but nobody had a systematic view of how customers were actually using it.


What we already know?
I reviewed existing beta tests and search behaviour data to avoid starting from zero. Two things became clear:
Rich behavioral data existed in conversation logs, but no framework to analyze it systematically
The internal AI tool was tagging conversations too broadly to surface meaningful patterns
This told me where to focus: I didn't need more qualitative research. I needed a way to make the existing data tell its story.

Evaluating the current experience using JTBD
I mapped the current assistant experience using a Jobs-to-be-Done framework to understand how well it was meeting user needs. Two patterns stood out immediately:
Users asked for nuanced, context-rich recommendations —the assistant responded with basic keyword outputs
Failure points were consistent but invisible—the evaluation tool couldn't distinguish a good interaction from a bad one

MY APPROACH
The Human-in-the-Loop Framework
I knew I couldn't answer these questions through traditional research alone, the scale of user interactions required a different approach. Thousands of real user conversations were happening every day but we lacked a systematic way to learn from them.
My approach was two-fold:
FIRST PART
Analyzing 200+ user conversations
To understand how users actually engaged, I developed an automated Google Sheet to pull 200 anonymous conversations and systematically code them across three dimensions:
User Intent
Categorized the purpose of each query to map what users were actually trying to achieve: outfit inspiration, occasion-based search, style discovery—not simple keyword searches.
Performance Evaluation
Rated each assistant response and compared it to the machine's own evaluation. Divergences between human and machine judgment revealed exactly where critical failures were hiding.
Failure Taxonomy
Built a custom taxonomy to tag every failed interaction: Misinterpretation, Hallucination (non-existent products recommended), Forgotten context across multi-turn conversations, Static response despite dissatisfaction signals
SECOND PART
Scaling what human analysis revealed
Manual analysis revealed critical nuances the machine evaluation was missing.
The gap: I could see in the conversations that users were asking for occasion-specific outfits, style inspiration, and multi-query explorations, but the internal AI tool tagged 77% of everything as simply "Search."
I worked with engineering to redesign the tagging system:
Redesigned tags to capture the full range of user intent
Built a repeatable human-in-the-loop validation process for each model iteration
Established weekly cross-functional review sessions to catch issues in real time
KEY INSIGHTS & NEXT STEPS
Conversation analysis revealed what to look for, tooling improvements made it possible to look at scale.
Both tracks fed the same outcome: a clear, prioritized picture of where the assistant was failing users—and what to do about it.
INSIGHT 1
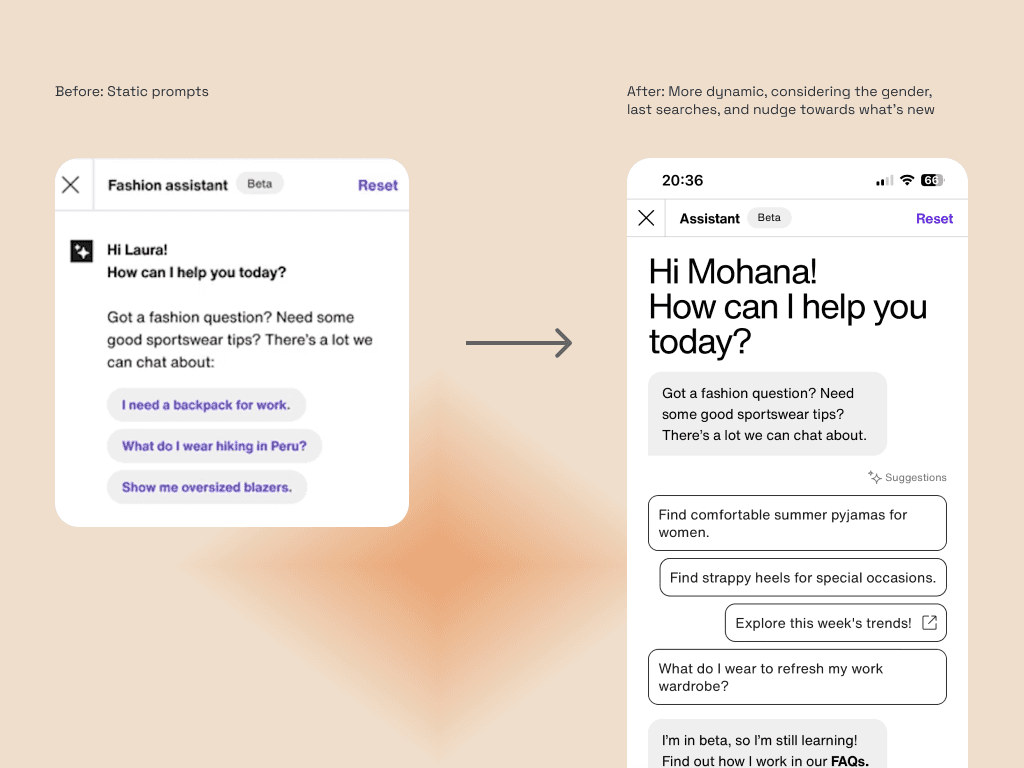
Suggestive prompts were a missed opportunity for a first-time user experience
Key finding
Generic prompts failed to engage users from the start. They often led to simple text outputs, hiding the assistant's dynamic capabilities and preventing meaningful discovery.
Action
Shifted from static prompts to dynamic, personalized "conversation starters" based on user behavior and seasonal trends.
Impact
Aimed to increase the number of high-value actions (HVAs). Meaningful conversations that moved users forward in their discovery journey, directly impacting customer lifetime value and product adoption.
INSIGHT 2
The assistant was blind to its own failures
Key finding
Repeated "more options" requests without any product clicks were a clear dissatisfaction signal, but the assistant treated them as positive engagement. Because of this users were stuck in a loop of poor recommendations while our metrics showed everything was fine.
Action
I documented these non-verbal dissatisfaction patterns and collaborated with the team to design a feedback loop. We implemented proactive nudges that prompted users for more details after repeated "more options" requests.
Impact
Positive user engagement: the assistant could actively learn from dissatisfaction signals and refine recommendations in real time
More accurate success metrics: stopped counting repeated requests as positive engagement, giving us a truer measure of customer satisfaction

INSIGHT 3
Without granular tagging, we were flying blind at scale
Key finding
The machine evaluation system used broad, generic tags that obscured a wide range of unique user behaviors. "Search" alone accounted for 77% of all queries—making it impossible to understand what customers actually needed or where the experience was consistently failing them.
Action
Redesigned the tagging taxonomy to capture the full range of user intent, breaking broad categories into specific, meaningful intent types
Impact
The redesigned tagging system provided a granular, scalable understanding of user needs. The team could identify which use cases were underperforming, build a focused product roadmap, and monitor performance at scale—directly contributing to the 14% HVAs increase in the first month of launch.

REFLECTIONS
Takeaways
Technical skills unlock research independence
I didn't wait for someone to pull conversation data for me. Using SQL to query live conversations directly meant I could start analyzing the same day. This speed built trust with the engineering team wasn't a bottleneck, I was keeping pace with their iterations.
Past research compounds when you bring it forward
I could have run a new foundational study on how customers discover fashion. Instead, I drew on previous JTBD research to quickly establish what "good" looked like for the assistant. This gave the team a baseline in days, not weeks, and let us focus iteration time on fixing what was broken, not rediscovering what we already knew.